Что значит кэш второго уровня частота. Галерея эффектов кэшей процессоров
1)Кеш-память
Кэш-память (от англ. cache, дословно - «заначка», «кубышка», амер.англ. cash - «наличные», «деньги под рукою») - память ЭВМ с быстрым доступом, где дублируется часть данных с другого носителя с более медленным доступом, или хранятся данные, для получения которых требуются «дорогие» (в смысле временных затрат) вычисления. Иногда для краткости кэш-память называют просто «кэш».Кэш-память позволяет обращаться к часто требуемым данным быстрее, чем это происходило бы без её использования. Процесс организации доступа через кэш-память называется кэшированием, а та память, которая кэшируется, называется основной памятью.
^
Кеширование оперативной памяти
Наиболее часто термин кеш-память используется для обозначения кеш
-памяти, находящейся между регистрами центрального процессора (ЦП)
и оперативной памятью (ОЗУ)
.
Кеш-память может давать значительный выигрыш в производительности
, потому что в настоящее время тактовая частота ОЗУ
значительно меньше тактовой частоты ЦП. Тактовая частота для кеш-памяти обычно не намного меньше частоты ЦП.
^
Уровни кеша
Разделение кеш-памяти на несколько уровней (до 3 для универсальных процессоров по состоянию на начало 2007 года). Кеш-память уровня N+1 всегда больше по размеру и медленнее по скорости обращения, чем кеш-память уровня N.
Самой быстрой памятью является кеш-память первого уровня (она же L1-cache), по сути, она является неотъемлемой частью процессора, поскольку расположена на одном с ним кристалле
и входит в состав функциональных блоков, без неё процессор не сможет функционировать. Память L1 работает на частоте процессора, и в общем случае обращение к ней может производится каждый такт (зачастую является возможным выполнять даже несколько чтений/записей одновременно), латентность доступа обычно равна 2-4 такта ядра, объём этой памяти обычно невелик - не более 64 Кб. Второй по быстродействию является L2 (в отличие от L1 её можно отключить с сохранением работоспособности процессора), кеш второго уровня, она обычно расположена либо на кристалле, как и L1, либо в непосредственной близости от ядра, например, в процессорном картридже (только в слотовых процессорах), в старых процессорах её располагали на системной плате. Объём L2 побольше - от 128 Кб до 1-4 Мб. Обычно латентность L2 расположенной на кристалле ядра составляет от 8 до 20 тактов ядра. Кеш третьего уровня наименее быстродействующий и обычно расположен отдельно от ядра ЦП, но он может быть очень внушительного размера и всё равно значительно быстрее чем оперативная память.
^
Ассоциативность кэша
Одна из фундаментальных характеристик кэш-памяти - уровень ассоциативности - отображает ее логическую сегментацию. Дело в том, что последовательный перебор всех строк кэша в поисках необходимых данных потребовал бы десятков тактов и свел бы на нет весь выигрыш от использования встроенной в ЦП памяти. Поэтому ячейки ОЗУ жестко привязываются к строкам кэш-памяти (в каждой строке могут быть данные из фиксированного набора адресов), что значительно сокращает время поиска. С каждой ячейкой ОЗУ может быть связано более одной строки кэш-памяти: например, n-канальная ассоциативность (n-way set associative) обозначает, что информация по некоторому адресу оперативной памяти может храниться в п мест кэш-памяти.
При одинаковом объеме кэша схема с большей ассоциативностью будет наименее быстрой, но наиболее эффективной.
^
Политика записи при кешировании
При чтении данных кеш-память даёт однозначный выигрыш в производительности. При записи данных выигрыш можно получить только ценой снижения надёжности. Поэтому в различных приложениях может быть выбрана та или иная политика записи кеш-памяти..
Существуют две основные политики записи кеш-памяти - сквозная запись (write-through) и отложенная запись (write-back).
сквозная запись подразумевает, что при изменении содержимого ячейки памяти, запись происходит синхронно и в кеш и в основную память.
отложенная запись подразумевает, что можно отложить момент записи данных в основную память, а записать их только в кеш. При этом данные будут выгружены в оперативную память только в случае обращения к ним какого либо другого устройства (другой ЦП, контроллер DMA) либо нехватки места в кеше для размещения других данных. Производительность , по сравнению со сквозной записью, повышается, но это может поставить под угрозу целостность данных в основной памяти, поскольку программный или аппаратный сбой может привести к тому, что данные так и не будут переписаны из кеша в основную память. Кроме того, в случае кеширования оперативной памяти, когда используются два и более процессоров, нужно обеспечивать согласованность данных в разных кешах.
Кеширование внешних накопителей
Многие периферийные устройства хранения данных используют кеш для ускорения работы, в частности, жёсткие диски используют кеш-память от 1 до 16 Мб (модели с поддержкой NCQ /TCQ используют её для хранения и обработки запросов), устройства чтения CD/DVD/BD-дисков так же кешируют прочитанную информацию для ускорения повторного обращения.
Операционная система так же использует часть оперативной памяти в качестве кеша дисковых операций (в том числе для внешних устройств, не обладающих собственной кеш-памятью, например, USB-flash, дисковод для дискет).
^
Кеширование интернет-страниц
Процесс сохранения часто запрашиваемых документов на промежуточных прокси-серверах
или машине пользователя, с целью предотвращения их постоянной загрузки с сервера-источника и уменьшения трафика
. Т.е. перемещение информации поближе к пользователю. Управление кэшированием осуществляется при помощи HTTP-заголовков
^
Кеширование результатов работы
Многие программы записывают куда-либо промежуточные или вспомогательные результаты работы, чтобы не вычислять их каждый раз, когда они понадобятся. Это ускоряет работу, но требует дополнительной памяти (оперативной или дисковой). Примером такого кеширования является индексирование
баз данных.
2) Intel 80286 (также известный как i286) - 16-битный x86 -совместимый процессор второго поколения фирмы Intel выпущенный 1 февраля года. Данный процессор представляет собой усовершенствованный вариант процессора Intel 8086 и был в 3-6 раз быстрее него. Процессор применялся, в основном, в IBM PC совместимых ПК.
Описание
Процессоры i286 разрабатывались параллельно процессорам Intel 80186 / , однако в нём отсутствовали некоторые модули, имевшиеся в процессоре Intel 80186. Процессор i286, выпускался в точно таком же корпусе как и i80186 - LCC, а также в корпусах типа PGA с 68 выводами. В новом процессоре было увеличено количество регистров , добавлены новые инструкции, добавлен новый режим работы процессора - защищённый режим . Процессор имел 6 байтовую очередь (как и Intel 8086). Шины адреса и данных теперь не мультиплексируются (то есть, адреса и данные передаются по разным ножкам). Шина адреса увеличена до 24 бит, таким образом объем ОЗУ может составлять 16 Мбайт. Процессор не умел выполнять операции над числами с плавающей запятой, для выполнения таких операций был необходим математический сопроцессор , например Intel 80287.Регистры
К 14 регистрам процессора Intel 8086 были добавлены 11 новых регистров, необходимых для реализации защищённого режима и других функций: регистр слово состояния машины, 16 бит (MSW); регистр задачи, 16 бит (TR); регистры дескрипторной таблицы , один 64-битный и два 40-битных (GDTR, IDTR, LDTR) и 6 регистров расширения сегментных регистров, 48 бит.Режимы работы процессора i286
В процессоре i286 было реализовано два режима работы - защищённый режим и реальный режим . В реальном режиме работы процессор был полностью совместим с процессорами x86 выпускавшимися до этого, то есть процессор мог выполнять программы предназначенные для Intel 8086/8088/8018x без повторного ассемблирования или с переассемблированием с минимальными модификациями. В формировании адреса участвовали только 20 линий шины данных, поэтому максимальный объём адресуемой памяти, в этом режиме, остался прежним - 1 Мбайт. В защищённом режиме процессор мог адресовать до 1 Гбайт виртуальной памяти (при этом объем реальной памяти составлял не более 16 Мбайт), за счёт изменения механизма адресации памяти. Переключение из реального режима в защищенный происходит программно и относительно просто, однако для обратного перехода необходим аппаратный сброс процессора, который в IBM PC-совместимых машинах осуществлялся обычно с помощью контроллера клавиатуры. Для отслеживания текущего режима работы процессора используется регистр слово состояния машины (MSW). Программы реального режима без модификаций в защищенном режиме исполняться не могут, так же как и программы BIOS машины.
Физический адрес формируется следующим образом. В сегментных регистрах хранится селектор , содержащий индекс дескриптора в таблице дескрипторов (13 бит), 1 бит, определяющий к какой таблице дескрипторов будет производиться обращение (к локальной или к глобальной) и 2 бита запрашиваемого уровня привилегий. Далее происходит обращение к соответствующей таблице дескрипторов и соответствующему дескриптору, который содержал начальный, 24-битный, адрес сегмента, размер сегмента и права доступа. После чего вычислялся необходимый физический адрес, путём сложения адреса сегмента со смещением, хранящемся в 16-разрядном указательном регистре.
Однако защищённый режим в процессоре Intel 80286 обладал и некоторыми недостатками, такими как, несовместимость с программами, написанными для реального режима MS-DOS, для перехода из защищенного режима в реальный режим требовался аппаратный сброс процессора.
^
Защищённый режим
Режим защиты памяти. Разработан фирмой Digital Equipments (DEC) для 32-разрядных компьютеров VAX-11. Основная мысль сводится к формированию таблиц описания памяти, которые определяют состояние её отдельных сегментов/страниц и т.п. При нехватке памяти операционная система может выгрузить часть данных из оперативной памяти на диск, а в таблицу описаний внести указание на отсутствие этих данных в памяти. При попытке обращения к отсутствующим данным процессор сформирует исключение (разновидность прерывания) и отдаст управление операционной системе, которая вернёт данные в память, а затем вернёт управление программе. Таким образом для программ процесс подкачки данных с дисков происходит незаметно.
Механизм защиты памяти применяется и в процессорах других производителей.
Реальный режим (или режим реальных адресов) - это название было дано прежнему способу адресации памяти
после появления 286-го процессора
, поддерживающего защищённый режим
.
^
Техническое описание
При таком способе организации памяти содержимое регистра
указателя сегмента умножалось на 16, то есть сдвигалось влево на 4 бита
и суммировалось с указателем. То есть, адреса 0400h:0000h и 0000h:4000h ссылаются на одинаковый адрес, так как 400h*16=4000h. Такой способ позволял адресовать 1 Мб + 64 Кб - 16 байт памяти, но из-за наличия в ранних процессорах только 20 адресных линий адресовался только 1 мегабайт.
Использование
В этом режиме процессоры работали только в старых версиях DOS . Адресовать в реальном режиме дополнительную память за пределами 1 Мб было нельзя. Впоследствии независимые программисты нашли способ обхода данного ограничения. Несмотря на то, что фирма Intel не предусмотрела возврат процессора 80286 из защищённого в реальный режим, был найден способ его перезагрузки. После такой перезагрузки возможность доступа к верхним блокам памяти оставалась. Впоследствии 386 процессоры позволили производить аналогичные действия без ухищрений и драйвер himem, выполняющий данные действия, был введён в операционную систему MS DOS . В дальнейшем это приводило к несовместимости некоторых программ.Затем от реального режима стали уходить с помощью программ-менеджеров защищённого режима, работающих в среде DOS, таких как: rtm, dpmi, DOS16M, DOS4G, DOS4GW. Некоторые из которых даже позволяли использование виртуальной памяти в среде DOS включением специальных управляющих переменных (например: DOS4GVM=ON).
Впоследствии, для полного отказа от реального режима, в защищённый режим был введён ещё один специальный режим виртуальных адресов V86. При этом программы получают возможность использовать прежний способ вычисления линейного адреса, не выходя из защищённого режима процессора. Данный режим позволил организовать работу прежней системы DOS внутри новых многозадачных систем Microsoft Windows .
Виртуальный режим
Помимо реального и защищённого режима работы, в процессорах i80386 и i80486 предусмотрен режим виртуального процессора 8086 (виртуальный режим), в который процессор может войти из защищённого режима. Виртуальный режим позволяет эмулировать процессор i8086, находясь в защищённом режиме. Это, в частности, даёт возможность в мультизадачной операционной системе организовать одновременное выполнение нескольких программ, ориентированных на процессор i8086.
^
3)Архитектура двойной независимой шины
Архитектура
построения процессора
, при которой данные передаются по двум шинам
независимо друг от друга, одновременно и параллельно.
Снимает многие проблемы пропускной способности компьютерных платформ , была разработана фирмой Intel для удовлетворения запросов прикладных программ , а также для обеспечения возможности дальнейшего развития новых поколений процессоров.
Наличие двух независимых шин дает возможность процессору получать доступ к данным , передающимся по любой из шин одновременно и параллельно, в отличие от последовательного механизма, характерного для систем с одной шиной.
Механизм работы
Архитектура двойной независимой шины использует две шины: "шину кэш 2-го уровня(L2)(512 KB )" и "системную шину" - от процессора к основной памяти .
Архитектура двойной независимой шины, к примеру, более чем в 3 раза ускоряет работу кэш 2-го уровня процессора Pentium II с тактовой частотой 400 МГц по сравнению с кэш L2 процессора Pentium . С увеличением тактовых частот процессоров Pentium II, возрастет и скорость доступа к кэш L2.
Конвейер системной шины обеспечивает одновременно множество взаимодействий,увеличивая поток информации в системе и существенно повышая общую производительность .
Дворовый турнир:
1. Тактовую частоту измеряют в: ГГц
2. Гипертекст это: Текст, в котором может осуществлятся переход по выделенным меткам
3. Перезаписываемые лазерные диски называются: DVD-RW
4. Принтер предназначен для: Вывода информации на бумагу
5. Программой архиватором называют: Программу для сжатия файлов
6. Производительность компьютера зависит от: Тактовой частоты процессора
7. Компьютерные вирусы: Создаются людьми специльно для нанесения ущерба ПК
8. Наименьшей единицей измерения информации является: бит
9. Жесткие диски получили название: Винчестер
10. Для подключения компьютера к телефонной сети используется: Модем
11. Сколько бит содержится в одном байте: 8
12. Выберите правильный порядок возрастания: Байт, килобайт, мегабайт, гигабайт
13. Для долговременного хранения информации служит: Жесткий диск
14. Какая программа обязательна для установки на компьютер: Операционная система
15. Процессоры различаются между собой: Разрядностью и тактовой частотой
Городской турнир:
1. Системное время компьютера постоянно сбрасывается, как решить проблему: Заменить батарейку BIOS
2. Какой тип кабеля наиболее восприимчив к электронным помехам: Неэкранированная витая пара
3. Какой из перечисленных IP-адресов является корректным с точки зрения формата: 192.168.0.3
4. Что такое браузер: Программа для просмотра интернет-страниц
5. Какое из устройств не относится к HID устройствам: Процессор
6. Укажите максимально быстрый тип кэша в процессоре: L1
7. Какое устройство необходимо внедрить в сеть для фильтрации трафика на границе между внешней и внутренней локальной сетью, пропуская только разрешенные пакеты: Межсетевой экран
8. Объем информации в DVD: 4.7 Гбайт
9. Графика в виде совокупности точек называется: Растровой
10. На задней панели компьютера расположен 25-ти контактный разъем типа «папа». Что это: COM порт
11. Витая пара, коаксиальный, оптоволоконный - это: Кабели, используемые для создания сети
12. Что из перечисленного происходит при использовании RAID-массивов: Повышается надёжность хранения данных
13. Компьютер, подключенный к Интернет, обязательно имеет: IP-адрес
14. Какая из файловых систем предназначена для оптических носителей: UDF
15. Элементарным объектом, используемым в растровом графическом редакторе является: Пиксель
Региональный турнир:
1. Какой сетевой протокол для работы использует утилита ping: ICMP
2. Какой протокол проверяет соответствие ip-адресов mac-адресам: ARP
3. Для каких целей служит система DNS: Для получения информации о доменах
4. Какой из перечисленных параметров клиент не может получить от DHCP cервера: IP-адрес SMTP сервера
5. Какой номер порта официально выделен IANA для протокола SMTP: 25
6. Какая технология предусмотрена специально на случай сбоя жесткого диска сервера: RAID
7. Какой вид атаки осуществляется для перехвата пакетов: Снифинг
8. Какую утилиту из необходимо использовать для сканирования IP-сетей: nmap
9. Какой из перечисленных протоколов реализует гарантированную доставку информационных пакетов: Протокол TCP
10. Какая команда Windows XP позволяет вывести на экран таблицу маршрутизации: route
11. Какой протокол не является протоколом электронной почты: HTTP
12. Какой из перечисленных протоколов реализует не гарантированную доставку информационных пакетов: Протокол IP
13. При помощи какой команды Windows возможно проверить наличие TCP-сервера на произвольном порту удаленного компьютера: telnet
14. На каком уровне сетевой модели OSI функционирует маршрутизатор: Сетевой
15. Какое из перечисленых средств применяется для диагностики уязвимостей серверов: Сканер XSpider
Федеральный турнир:
1. В ANSI/SQL какой из операторов позволяет объединить результаты нескольких запросов, не исключая одинаковые строки: union
2. Какой тип сервера позволит организовать общий доступ нескольких рабочих станций в Интернет: Proxy-сервер
3. HTML. Что определяет атрибут colspan тега : Объединяет ячейки по горизонтали
4. В ANSI/SQL какой из перечисленных логических порядков выполнения инструкции select верен: from -> where -> group by -> join
5. HTML. Какой тег нужно использовать для отображения текста со всеми пробелами:
6. В ANSI/SQL какой из перечисленных ограничений в команде create table определяет значение, автоматически выставляемое при добавлении записи, если пользователь не введет его: default
7. Какая команда Windows позволяет получить список TCP соединений: netstat-a
8. HTML. Какой тег не является параметром тега : href
9. HTML. Какое написание из приведенных вариантов правильное:
10. HTML. Какой из приведенных фрагментов кода выравнивает содержимое ячейки по правому краю:
11. HTML. Какой тег определяет фоновую картинку: body background
12. HTML. Какой тег является тегом перевода строки:
13. В ANSI/SQL какое из перечисленных ключевых слов запроса применяется для сортировки по убыванию: desc
14. HTML. В какой строке содержится корректный синтаксис: body{color:black}
15. HTML. Какой тег не является тегом организации списка:Международный турнир:
1. Что в С++ обозначается ключевым словом catch: Блок обработки исключения
2. Java. Какой из перечисленных объявлений дробного литерала не является правильным: double d = 1e0;
3. С++. Область видимости переменной, объявленной внутри блока распространяется: От места объявления переменной до конца блока
4. Java. Какой модификатор требуется применить, чтобы некоторые поле объекта не сериализовалось соответствующим механизмом по умолчанию: transient
5. Java. Какое отличие существует между операторами break и continue: continue может использоваться только внутри цикла
6. Что из перечисленного является объявлением в С++: int *a
7. Что в ANSI/SQL операторе select позволяет выбрать все имена полей из списка таблиц: *
8. Java. Какой результат выполнения указанной строки: int i = Integer.MAX_VALUE+10: Значением i станет отрицательное число
9. Java. Какие из приведенных фрагментов кода приведут к ошибке компиляции из-за некорректного использования комментариев: circle.get/*comment*/Radius();
10. В С++ оператор typeid() возвращает: Ссылку на тип стандартной библиотеки, называемой type_info
11. Как в С++ выглядит операция разрешения контекста (операция разрешения области видимости): ::
12. Чем в С++ классы отличаются от структур: Модификатором доступа к полям и функциям-членам по умолчанию
13. В ANSI/SQL какое ключевое слово служит для создания псевдонима столбцу результата выборки: ALIAS
14. Для чего в С++ предназначен оператор sizeof: Для определения количества байт, занимаемых типом
15. Как в С++ правильно вызвать эту функцию: int sum (int a, int b) {return a + b}: sum(7,8);
- Перевод
Почти все разработчики знают, что кэш процессора - это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти - определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
В этой статье мы рассмотрим ряд примеров иллюстрирующих различные особенности работы кэшей и их влияние на производительность. Примеры будут на C#, выбор языка и платформы не так сильно влияет на оценку производительности и конечные выводы. Естественно, в разумных пределах, если вы выберите язык, в котором чтение значения из массива равносильно обращению к хеш-таблице, никаких результатов пригодных к интерпретации вы не получите. Курсивом идут примечания переводчика.
Habracut - - -
Пример 1: доступ к памяти и производительность
Как вы думаете, насколько второй цикл быстрее первого?int arr = new int ;// первый
for (int i = 0; i < arr.Length; i++) arr[i] *= 3;// второй
for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;
Первый цикл умножает все значения массива на 3, второй цикл только каждое шестнадцатое значение. Второй цикл совершает только 6% работы первого цикла, но на современных машинах оба цикла выполняются примерно за равное время: 80 мс и 78 мс соответственно (на моей машине).Разгадка проста - доступ к памяти. Скорость работы этих циклов в первую очередь определяется скоростью работы подсистемы памяти, а не скоростью целочисленного умножения. Как мы увидим в следующем примере, количество обращений к оперативной памяти одинаково и в первом и во втором случае.
Пример 2: влияние строк кэша
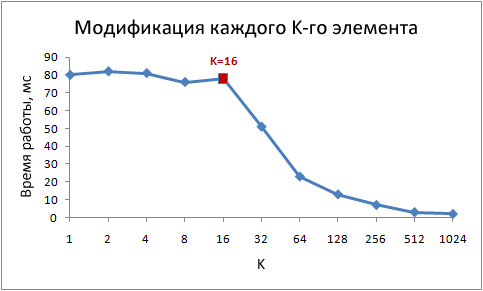
Копнём глубже - попробуем другие значения шага, не только 1 и 16:for (int i = 0; i < arr.Length; i += K /* шаг */ ) arr[i] *= 3;
Вот время работы этого цикла для различных значений шага K:
Обратите внимание, при значениях шага от 1 до 16 время работы практически не изменяется. Но при значениях больше 16, время работы уменьшается примерно вдвое каждый раз когда мы увеличиваем шаг в два раза. Это не означает, что цикл каким-то магическим образом начинает работать быстрее, просто количество итераций при этом так же уменьшается. Ключевой момент - одинаковое время работы при значениях шага от 1 до 16.
Причина этого в том, что современные процессоры осуществляют доступ к памяти не побайтно, а небольшими блоками, которые называют строками кэша. Обычно размер строки составляет 64 байта. Когда вы читаете какое-либо значение из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро.
Из-за того, что 16 значений типа int занимают 64 байта, циклы с шагами от 1 до 16 обращаются к одинаковому количеству строк кэша, точнее говоря, ко всем строкам кэша массива. При шаге 32, обращение происходит к каждой второй строке, при шаге 64, к каждой четвёртой.
Понимание этого очень важно для некоторых способов оптимизации. От места расположения данных в памяти зависит число обращений к ней. Например, из-за невыровненных данных может потребоваться два обращения к оперативной памяти, вместо одного. Как мы выяснили выше, скорость работы при этом будет в два раза ниже.
Пример 3: размеры кэшей первого и второго уровня (L1 и L2)
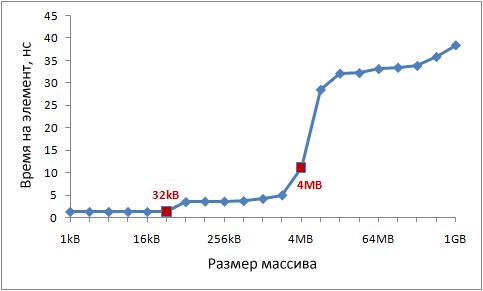
Современные процессоры, как правило, имеют два или три уровня кэшей, обычно их называют L1, L2 и L3. Для того, чтобы узнать размеры кэшей различных уровней, можно воспользоваться утилитой CoreInfo или функцией Windows API GetLogicalProcessorInfo . Оба способа так же предоставляют информацию о размере строки кэша для каждого уровня.На моей машине CoreInfo сообщает о кэшах данных L1 объёмом по 32 Кбайт, кэшах инструкций L1 объёмом по 32 Кбайт и кэшах данных L2 объёмом по 4 Мбайт. Каждое ядро имеет свои персональные кэши L1, кэши L2 общие для каждой пары ядер:
Logical Processor to Cache Map: *--- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 *--- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 -*-- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64 **-- Unified Cache 0, Level 2, 4 MB, Assoc 16, LineSize 64 --*- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 --*- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 ---* Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64 --** Unified Cache 1, Level 2, 4 MB, Assoc 16, LineSize 64
Проверим эту информацию экспериментально. Для этого, пройдёмся по нашему массиву инкрементируя каждое 16-ое значение - простой способ изменить данные в каждой строке кэша. При достижении конца, возвращаемся к началу. Проверим различные размеры массива, мы должны увидеть падение производительности когда массив перестаёт помещаться в кэши разных уровней.Код такой:
int steps = 64 * 1024 * 1024; // количество итераций
int lengthMod = arr.Length - 1; // размер массива -- степень двойкиfor (int i = 0; i < steps; i++)
{
// x & lengthMod = x % arr.Length, ибо степени двойки
arr[(i * 16) & lengthMod]++;
}
Результаты тестов:
На моей машине заметны падения производительности после 32 Кбайт и 4 Мбайт - это и есть размеры кэшей L1 и L2.
Пример 4: параллелизм инструкций
Теперь давайте взглянем на кое-что другое. По вашему мнению, какой из этих двух циклов выполнится быстрее?int steps = 256 * 1024 * 1024;
int a = new int ;// первый
for (int i = 0; i < steps; i++) { a++; a++; }// второй
for (int i = 0; i < steps; i++) { a++; a++; }
Оказывается, второй цикл выполняется почти в два раза быстрее, по крайней мере, на всех протестированных мной машинах. Почему? Потому, что команды внутри циклов имеют разные зависимости по данным. Команды первого имеют следующую цепочку зависимостей:Во втором цикле зависимости такие:
Функциональные части современных процессоров способны выполнять определённое число некоторых операций одновременно, как правило, не очень большое число. Например, возможен параллельный доступ к данным из кэша L1 по двум адресам, так же возможно одновременное выполнение двух простых арифметических команд. В первом цикле процессор не может задействовать эти возможности, но может во втором.
Пример 5: ассоциативность кэша
Один из ключевых вопросов, на который необходимо дать ответ при проектировании кэша - могут ли данные из определённой области памяти храниться в любых ячейках кэша или только в некоторых из них. Три возможных решения:Кэши прямого отображения подвержены конфликтам, например, когда две строки соревнуются за одну ячейку, поочерёдно вытесняя друг-друга из кэша, эффективность очень низка. С другой стороны, полностью ассоциативные кэши, хотя и лишены этого недостатка, очень сложны и дороги в реализации. Частично-ассоциативные кэши - типичный компромисс между сложностью реализации и эффективностью.
- Кэш прямого отображения , данные каждой строки кэша в оперативной памяти хранятся только в одной заранее определённой ячейке кэша. Простейший способ вычисления отображения: индекс_строки_в_памяти % количество_ячеек_кэша. Две строки, отображённые на одну и ту же ячейку, не могут находится в кэше одновременно.
- N-входовый частично-ассоциативный кэш , каждая строка может храниться в N различных ячейках кэша. Например, в 16-входовом кэше строка может храниться в одной из 16-ти ячеек составляющих группу. Обычно, строки с равными младшими битами индексов разделяют одну группу.
- Полностью ассоциативный кэш , любая строка может быть сохранена в любую ячейку кэша. Решение эквивалентно хеш-таблице по своему поведению.
К примеру, на моей машине кэш L2 размером в 4 Мбайт является 16-входовым частично-ассоциативным кэшем. Вся оперативная память разделена на множества строк по младшим битам их индексов, строки из каждого множества соревнуются за одну группу из 16 ячеек кэша L2.
Так как кэш L2 имеет 65 536 ячеек (4 * 2 20 / 64) и каждая группа состоит из 16 ячеек, всего мы имеем 4 096 групп. Таким образом, младшие 12 битов индекса строки определяют к какой группе относится эта строка (2 12 = 4 096). В результате, строки с адресами кратными 262 144 (4 096 * 64) разделяют одну и ту же группу из 16-ти ячеек и соревнуются за место в ней.
Чтобы эффекты ассоциативности проявили себя, нам необходимо постоянно обращаться к большому количеству строк из одной группы, например, используя следующий код:
public static long UpdateEveryKthByte(byte arr, int K)
{
const int rep = 1024 * 1024; // количество итерацийStopwatch sw = Stopwatch.StartNew();
int p = 0;
for (int i = 0; i < rep; i++)
{
arr[p]++;P += K; if (p >= arr.Length) p = 0;
}Sw.Stop();
return sw.ElapsedMilliseconds;
}
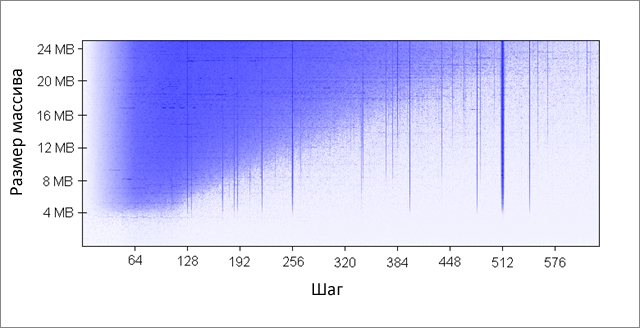
Метод инкрементирует каждый K-ый элемент массива. По достижении конца, начинаем заново. После довольно большого количества итераций (2 20), останавливаемся. Я сделал прогоны для различных размеров массива и значений шага K. Результаты (синий - большое время работы, белый - маленькое):
Синим областям соответствуют те случаи, когда при постоянном изменении данных кэш не в состоянии вместить все требуемые данные одновременно . Яркий синий цвет говорит о времени работы порядка 80 мс, почти белый - 10 мс.
Разберёмся с синими областями:
Обнаруженные эффекты сохраняются и при больших значениях параметров:
- Почему появляются вертикальные линии? Вертикальные линии соответствуют значениям шага при которых осуществляется доступ к слишком большому числу строк (больше 16-ти) из одной группы. Для таких значений, 16-входовый кэш моей машины не может вместить все необходимые данные.
Некоторые из плохих значений шага - степени двойки: 256 и 512. Для примера рассмотрим шаг 512 и массив в 8 Мбайт. При этом шаге, в массиве имеются 32 участка (8 * 2 20 / 262 144), которые ведут борьбу друг с другом за ячейки в 512-ти группах кэша (262 144 / 512). Участка 32, а ячеек в кэше под каждую группу только 16, поэтому места на всех не хватает.
Другие значения шага, не являющиеся степенями двойки, просто невезучие, что вызывает большое количество обращений к одинаковым группам кэша, а так же приводит к появлению вертикальных синих линий на рисунке. На этом месте любителям теории чисел предлагается задуматься.
- Почему вертикальные линии обрываются на границе в 4 Мбайт? При размере массива в 4 Мбайт или меньше, 16-входовый кэш ведёт себя так же как и полностью ассоциативный, то есть может вместить все данные массива без конфликтов. Имеется не более 16-ти областей ведущих борьбу за одну группу кэша (262 144 * 16 = 4 * 2 20 = 4 Мбайт).
- Почему слева вверху находится большой синий треугольник? Потому, что при маленьком шаге и большом массиве кэш не в состоянии уместить все необходимые данные. Степень ассоциативности кэша играет тут второстепенную роль, ограничение связано с размером кэша L2.
Например, при размере массива в 16 Мбайт и шаге 128, мы обращаемся к каждому 128-му байту, таким образом, модифицируя каждую вторую строку кэша массива. Чтобы сохранить каждую вторую строку в кэше, необходим его объём в 8 Мбайт, но на моей машине есть только 4 Мбайт.
Даже если бы кэш был полностью ассоциативным, это не позволило бы сохранить в нём 8 Мбайт данных. Заметьте, что в уже рассмотренном примере с шагом 512 и размером массива 8 Мбайт, нам необходим только 1 Мбайт кэша, чтобы сохранить все нужные данные, но это невозможно сделать из-за недостаточной ассоциативности кэша.
- Почему левая сторона треугольника постепенно набирает свою интенсивность? Максимум интенсивности приходится на значение шага в 64 байта, что равно размеру строки кэша. Как мы увидели в первом и во втором примере, последовательный доступ к одной и той же строке практически ничего не стоит. Скажем, при шаге в 16 байт, мы имеем четыре обращения к памяти по цене одного.
Так как количество итераций равно в нашем тесте при любом значении шага, то более дешёвый шаг в результате даёт меньшее время работы.
Ассоциативность кэша - интересная штука, которая может проявить себя при определённых условиях. В отличие от остальных рассмотренных в этой статье проблем, она не является настолько серьёзной. Определённо, это не то, что требует постоянного внимания при написании программ.
Пример 6: ложное разделение кэша
На многоядерных машинах можно столкнуться с другой проблемой - согласование кэшей. Ядра процессора имеют частично или полностью раздельные кэши. На моей машине кэши L1 раздельны (как и обычно), так же имеются два кэша L2, общие для каждой пары ядер. Детали могут различаться, но в целом современные многоядерные процессоры имеют многоуровневые иерархические кэши. Причём самые быстрые, но и самые маленькие кэши, принадлежат индивидуальным ядрам.Когда одно из ядер модифицирует значение в своём кэше, другие ядра больше не могут использовать старое значение. Значение в кэшах других ядер должно быть обновлено. Более того, должна быть обновлена полностью вся строка кэша , так как кэши оперируют данными на уровне строк.
Продемонстрируем эту проблему на следующем коде:
private static int s_counter = new int ;private void UpdateCounter(int position)
{
for (int j = 0; j < 100000000; j++)
{
s_counter = s_counter + 3;
}
}
Если на своей четырёхядерной машине я вызову этот метод с параметрами 0, 1, 2, 3 одновременно из четырёх потоков, то время работы составит 4.3 секунды . Но если я вызову метод с параметрами 16, 32, 48, 64, то время работы составит только 0.28 секунды .Почему? В первом случае, все четыре значения, обрабатываемые потоками в каждый момент времени, с большой вероятностью попадают в одну строку кэша. Каждый раз когда одно ядро увеличивает очередное значение, оно помечает ячейки кэша, содержащие это значение в других ядрах, как невалидные. После этой операции, все остальные ядра должны будут закэшировать строку заново. Это делает механизм кэширования неработоспособным, убивая производительность.
Пример 7: сложность железа
Даже теперь, когда принципы работы кэшей для вас не секрет, железо по-прежнему будет преподносить вам сюрпризы. Процессоры отличаются друг от друга методами оптимизации, эвристиками и прочими тонкостями реализации.Кэш L1 некоторых процессоров может осуществлять параллельный доступ к двум ячейкам, если они относятся к разным группам, но если они относятся к одной, только последовательно. Насколько мне известно, некоторые даже могут осуществлять параллельный доступ к разным четвертинкам одной ячейки.
Процессоры могут удивить вас хитрыми оптимизациями. Например, код из предыдущего примера про ложное разделение кэша не работает на моём домашнем компьютере так, как задумывалось - в простейших случаях процессор может оптимизировать работу и уменьшить негативные эффекты. Если код немного модифицировать, всё встаёт на свои места.
Вот другой пример странных причуд железа:
private static int A, B, C, D, E, F, G;private static void Weirdness()
{
for (int i = 0; i < 200000000; i++)
{
<какой-то код>
}
}
Если вместо <какой-то код> подставить три разных варианта, можно получить следующие результаты:
Инкрементирование полей A, B, C, D занимает больше времени, чем инкрементирование полей A, C, E, G. Что ещё страннее, инкрементирование полей A и C занимает больше времени, чем полей A, C и E, G. Не знаю точно каковы причины этого, но возможно они связаны с банками памяти (да-да, с обычными трёхлитровыми сберегательными банками памяти, а не то, что вы подумали ). Имеющих соображения на этот счёт, прошу высказываться в комментариях.
У меня на машине вышеописанного не наблюдается, тем не менее, иногда бывают аномально плохие результаты - скорее всего, планировщик задач вносит свои «коррективы».
Из этого примера можно вынести следующий урок: очень сложно полностью предсказать поведение железа. Да, можно предсказать многое, но необходимо постоянно подтверждать свои предсказания с помощью измерений и тестирования.
Заключение
Надеюсь, что всё рассмотренное помогло вам понять устройство кэшей процессоров. Теперь вы можете использовать полученные знания на практике для оптимизации своего кода.




 Интерактивные игры для детей
Интерактивные игры для детей Экологические игры для детей среднего и старшего дошкольного возраcта Игры на экологическую тему картотека
Экологические игры для детей среднего и старшего дошкольного возраcта Игры на экологическую тему картотека Мочекаменная болезнь: лечение в зависимости от размера камней Как выйти из кс не получив бана
Мочекаменная болезнь: лечение в зависимости от размера камней Как выйти из кс не получив бана «Составь описание Выводы об уровне развития
«Составь описание Выводы об уровне развития